近日,一种基于GPU并行的快速近场动力学算法,实现了计算力学算法与计算机技术的深入交叉结合,为解决传统计算力学算法的效率问题找到了新的方向。
其成果发表在。作者为深圳北理莫斯科大学杨杨副教授,与南方科技大学刘轶军讲席教授、硕士研究生苏梓鑫。

近场动力学(Peridynamics)是一种有效解决断裂问题的方法。然而,其非局部理论使得计算过程较为耗时。并行计算是加速数值计算的有效途径,主要分为基于中央处理器(CPU)的并行计算和基于图形处理器(GPU)的并行计算。CPU并行计算更适合处理逻辑复杂的场景,例如消息传递接口(Message Passing Interface, MPI)和共享内存并行编程(Open Multi-Processing, OpenMP)等。而GPU并行计算则更适合处理逻辑简单但计算量大的场景,例如开放计算语言(Open Computing Language, OpenCL)和英伟达的统一计算设备架构(NVIDIA's Compute Unified Device Architecture, CUDA)等。由于近场动力学的非局部特性,每个材料点仅与其邻域内的点相互作用,这使得其非常适合进行并行化处理。
目前,基于GPU的近场动力学并行研究,大多集中在将串行程序转换为并行程序。许多优化策略带来的加速效果主要依赖于GPU自身性能的提升,而针对GPU硬件结构的优化相对较少。此外,GPU并行计算仍存在一些问题:用于存储邻域点的内存空间没有预设大小,导致线程和内存资源的低效使用,造成内存和计算资源的浪费,使得GPU在处理大规模问题时面临挑战;大多数GPU并行计算仍然严重依赖全局内存,未能充分利用CUDA的内存结构,导致内存带宽的浪费;大多数近场动力学并行算法缺乏通用性,一些算法可能限制了邻域的大小,仅能处理均匀分布且未受损的离散结构,或者限制了近场动力学理论的应用。
基于上述限制,本研究设计了一个成本效益高且性能优异的近场动力学模拟框架。该分析框架能够以高效的计算速率准确模拟键基和态基近场动力学问题。该算法采用了粒子并行模式,建立了一个通用的邻域生成模块用以优化存储,并提出了一种通用寄存器技术,用于高速访问寄存器内存,减少全局内存访问。该技术不仅消除了对邻域点数量的限制,还适用于材料点的非均匀分布。与现有基于串行程序和OpenMP并行的近场动力学算法程序相比,该算法分别可实现高达800倍和100倍的加速。在典型的百万级粒子模拟中,执行4000次迭代在单精度下可在5分钟内完成,在双精度下可在20分钟内完成,这在低端GPU PC上即可实现。这意味着,在处理复杂的材料设计和损伤模拟时,研究人员能够更快地获得结果,从而加速科学研究和工程应用的发展。
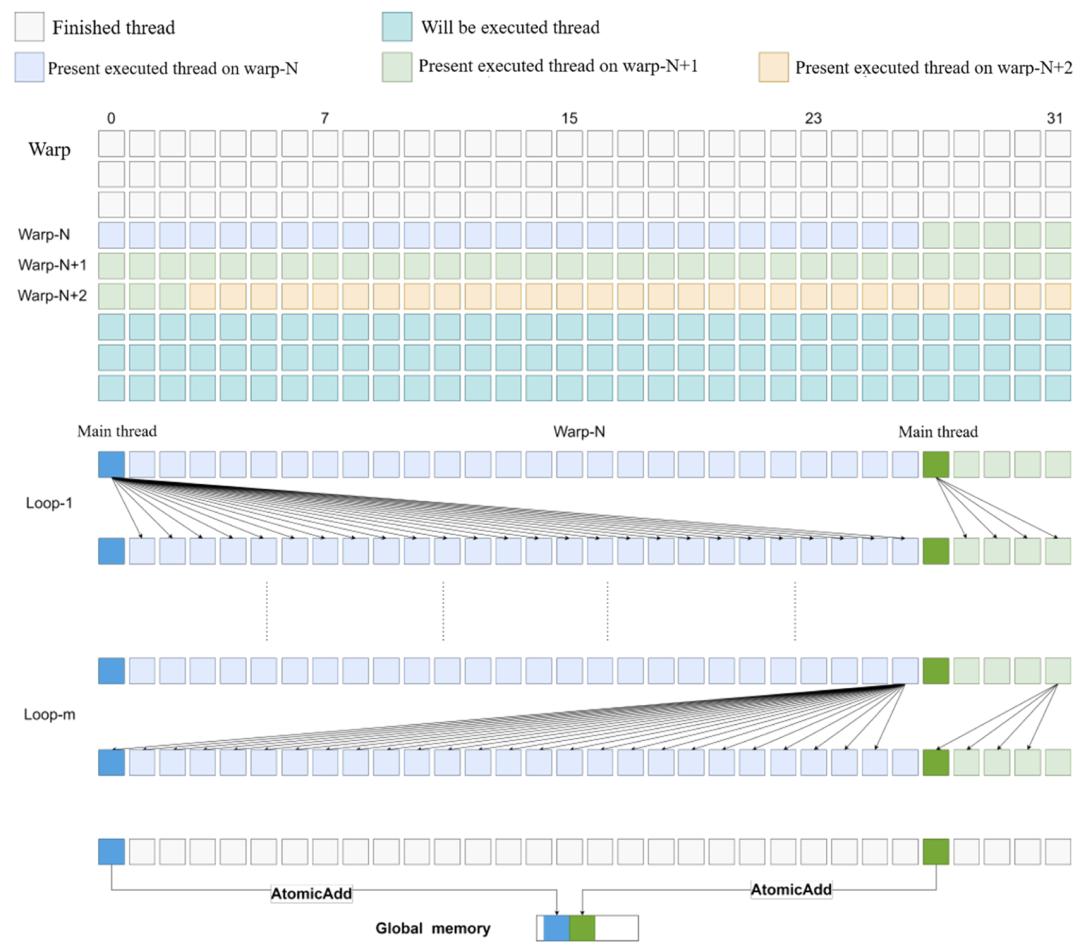
图1 通用寄存器优化算法示意图
这项技术的广泛应用将有助于推动多个领域的创新,特别是在需要高性能计算支持的行业中。通过利用消费级GPU的强大计算能力,研究人员能够更高效地解决复杂的物理问题,从而推动科技进步和产业升级。
原标题:《算法新成果!深圳高校师生开发!》



